
Интеллектуальный поиск — это класс поисковых систем, использующих технологии обработки естественного языка, машинного обучения, семантического анализа и генеративного ИИ. Они помогают понять контекст запроса пользователя, найти релевантную информацию и быстро сформировать качественный ответ. В частности, такие решения применяются для работы с корпоративными данными, документами и внутренними базами знаний.
В статье разбираем:
- технологии в основе интеллектуального поиска;
- задачи бизнеса, которые он закрывает;
- решения с интеллектуальным поиском на российском рынке.

Время прочтения: 18 минут
Краткое содержание
Системы интеллектуального поиска: как ИИ меняет работу с корпоративными документами
Что такое система интеллектуального поиска и чем она отличается от классической?
Какие технологии лежат в основе ИИ-поиска?
Источники знаний для интеллектуального поиска
Зачем бизнесу интеллектуальный поиск по документам: ключевые ситуации
Умный поиск по документам: решения на рынке
На что ориентироваться при выборе системы интеллектуального поиска
Итог
Что такое система интеллектуального поиска и чем она отличается от классической?
Какие технологии лежат в основе ИИ-поиска?
Источники знаний для интеллектуального поиска
Зачем бизнесу интеллектуальный поиск по документам: ключевые ситуации
Умный поиск по документам: решения на рынке
На что ориентироваться при выборе системы интеллектуального поиска
Итог
Системы интеллектуального поиска: как ИИ меняет работу с корпоративными документами
В большинстве компаний информация неравномерно распределена по разным системам.
Регламенты хранятся в базах знаний, договоры и отчёты — в файловых хранилищах и ECM-системах, а инструкции, технические задания и ответы на частые вопросы — на почте, в тасктрекерах. Часть знаний при этом вообще остаётся неоцифрованной. В результате формально информация доступна, но на практике её сложно найти быстро и без лишних усилий.
Из-за этого сотрудники тратят значительное время на поиск информации — до 25% рабочего времени, по данным Atlassian. Это влияет не только на удобство, но и на бизнес-показатели: замедляются процессы, растут издержки, снижается скорость принятия решений.
Именно здесь возникает потребность в системах интеллектуального поиска — современных решениях на базе генеративного ИИ и Retrieval-Augmented Generation (RAG).
Что такое система интеллектуального поиска и чем она отличается от классической?
Поиск на базе ИИ (или AI-powered enterprise search) — это решение нового поколения, которое сочетает полнотекстовый поиск, семантический и векторный подходы к извлечению данных, а также методы NLP и машинного обучения для более точной интерпретации.
Благодаря этому система понимает не только смысл запроса, но и стоящую за ним задачу, учитывает глубокий контекст, синонимы, профессиональную терминологию и объединяет данные из десятков разнородных источников.
В отличие от классического поиска, интеллектуальный поиск способен:
- обрабатывать большое количество разнородных источников и типов данных (текст, изображения, видео, аудио, данные с датчиков IoT/IIoT и машинные логи);
- анализировать паттерны, взаимосвязи и отношения между данными;
- определять истинное намерение пользователя и предоставлять контекстно зависимую информацию;
- синтезировать готовый ответ, суммировать информацию, цитировать источники и предлагать решение задачи, а не просто список ссылок.
Наглядно привели основные различия в таблице ниже.
В итоге выдача ИИ-поиска содержит точный и актуальный ответ, тем самым существенно сокращает время на поиск информации и минимизирует когнитивную нагрузку на сотрудника.

Какие технологии лежат в основе ИИ-поиска?
Современные системы интеллектуального поиска построены на многоуровневой архитектуре, которая решает две ключевые задачи:
- Глубоко проанализировать разрозненное содержимое данных и построить между ними осмысленные связи.
- Интерпретировать запрос пользователя с учётом контекста, роли, истории и прав доступа.
Для этого используется комбинация следующих технологий.
Обработка естественного языка (NLP) и большие языковые модели (LLM)
Методы обработки естественного языка (NLP) и современные LLM отвечают за понимание запроса на естественном языке: выделение интента, работу с профессиональной терминологией, синонимами, опечатками, аббревиатурами и отраслевым контекстом.
Векторный поиск (Vector search)
Документы и запросы преобразуются в эмбеддинги — представления данных в виде числовых векторов. Это позволяет находить релевантные материалы не только по словам, но и по смысловой близости.
Технология RAG (Retrieval-Augmented Generation)
Это основа современных интеллектуальных поисковых систем.
Процесс состоит из двух этапов:
- Retrieval-Augmented — извлечение и дополнение запроса найденными релевантными фрагментами из всех корпоративных источников с учётом прав доступа пользователя.
- Generation — генерация точного и структурированного ответа большой языковой моделью на основе найденных фрагментов.
Такая архитектура снижает риск галлюцинаций и позволяет формировать ответы на основе внутренних данных компании.
«Умный поиск — базовый функционал в современных реалиях. При этом технологии под капотом — это лишь часть успеха. Чтобы сотрудники и ИИ-агенты действительно приносили пользу, знания должны быть актуальными, понятными и применимыми.
При этом знания должны соответствовать требованиям ИИ-модели. Эти требования зачастую строже, чем для человека: если человеку достаточно выделить заголовок визуально, например жирным шрифтом, то для ИИ важно, чтобы структура была корректно размечена на уровне тегов (например, <h1>–<h6>). Тогда система сможет правильно интерпретировать и использовать информацию.
Это возможно только при наличии выстроенных процессов и культуры менеджмента знаний внутри компании».
Денис Кучеров, директор проектов Minerva Result.
Источники знаний для интеллектуального поиска
На практике важны не только технологии ИИ-поиска, но и качество источников. В большинстве компаний информация распределена по разным системам: CRM, базам знаний, тасктрекерам, внутренним порталам. Но для корпоративного интеллектуального поиска нужны структурированные и управляемые источники.
Единая база знаний
Основным и самым эффективным источником данных для интеллектуального поиска становится корпоративная база знаний. Здесь информация отбирается, актуализируется и приводится к формату, понятному как человеку, так и ИИ-модели.
Но качество ответа зависит не только от технологий поисковой системы, но и в большей степени от качества знаний в базе. Если данные устарели, дублируются или плохо структурированы, даже продвинутые алгоритмы не дадут полезного результата.
Одним из решений этой задачи является система управления знаниями Minerva Knowledge. Она позволяет централизованно собрать, структурировать и актуализировать информацию в базе знаний с учётом требований ИИ — от корректной разметки до управления доступами.
Также в ней доступны контроль версий и встроенные инструменты для создания и обновления контента: удобный совместный редактор, шаблоны и интеграция с Google Docs, Miro, «Яндекс Картами» и другими популярными сервисами.
Система не просто хранит информацию, а развивается вместе с компанией: обновления в контенте автоматически становятся доступными сотрудникам с учётом их ролей, что помогает быстрее внедрять изменения и снижает риск работы по устаревшим данным.
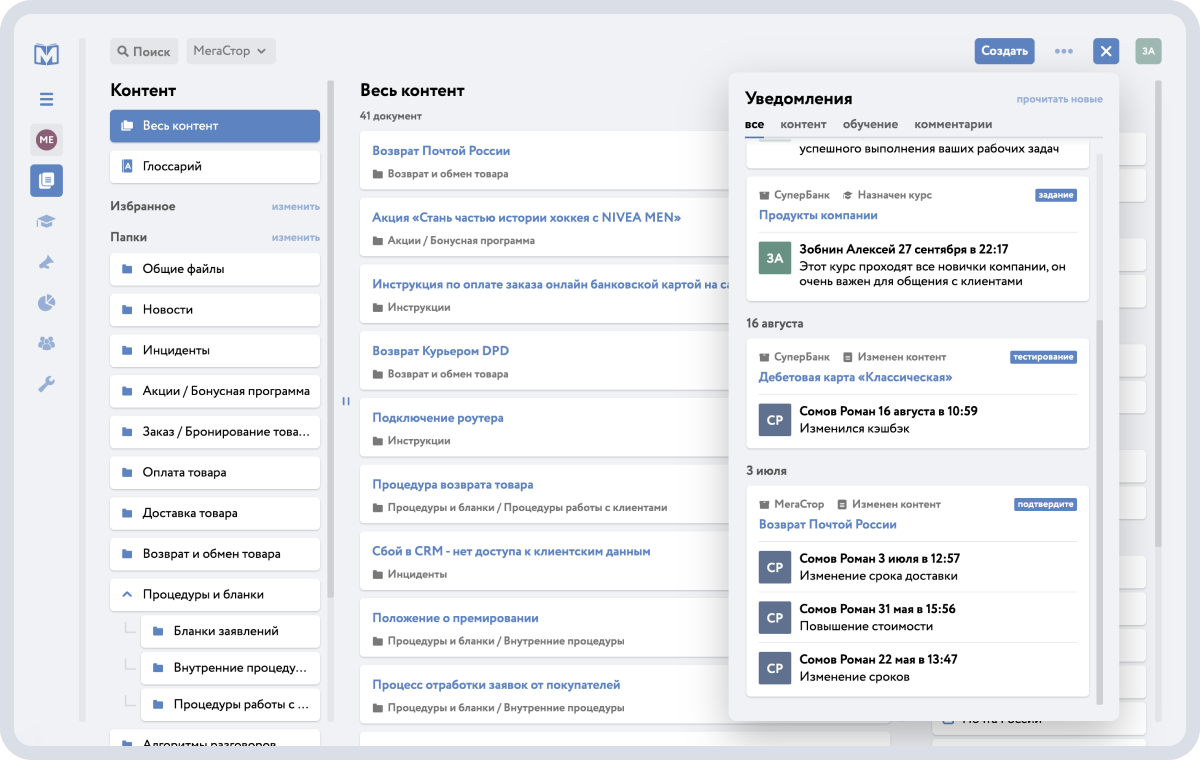
Уведомления об изменениях с подробным описанием приходят каждому пользователю
Также в Minerva Knowledge есть встроенный инструмент по миграции с зарубежных сервисов: Confluence, Notion и других wiki-платформ. Он автоматически может перенести все данные, включая графические объекты, диаграммы и видео.
Файловые хранилища
Файловые хранилища — один из основных источников корпоративной информации. К ним относятся облачные сервисы вроде Google Drive, OneDrive, Dropbox и SharePoint, а также локальные решения: сетевые папки, внутренние файловые серверы и другие системы хранения документов. В них удобно хранить большой массив документов: договоры, счета, инструкции, презентации, проектные материалы и другие рабочие файлы.
Но у таких систем есть типовые ограничения:
- Отсутствие единой структуры и дублирование — одни и те же документы могут лежать в разных папках в разных версиях. Поиск не может достоверно понять, какой файл является актуальным, поэтому даёт ответы на основе устаревшей или противоречивой информации.
- Лимитированные возможности в подготовке информации в нужном формате для обучения ИИ-агентов и внедрения интеллектуального поиска.
ECM
ECM — система для хранения данных и управления документооборотом. В таких системах обычно хранятся договоры, заявки, акты, служебные записки, кадровые и финансовые документы, а также другие материалы, для которых важны маршруты согласования, статусы, сроки хранения и юридическая значимость. Для ИИ-поиска эти данные также важны, но качество результатов может пострадать из-за ограничений системы.
Внутренние бизнес-системы
Внутренние бизнес-системы — это все корпоративные платформы, в которых хранится операционная информация о процессах, клиентах, сотрудниках и внутренних сервисах. К ним относятся CRM, ERP, HRM, Service Desk и другие системы, где фиксируются заявки, сделки, статусы, обращения, кадровые данные и рабочая история взаимодействий.
Такие системы создаются для контроля операций и бизнес-процессов, а не для создания качественных и полезных материалов, которые можно использовать для генерации готового решения. Поэтому информацию из бизнес-систем можно использовать в качестве дополнительных источников для систем интеллектуального поиска, а для основного источника выбирать базы знаний.
Зачем бизнесу интеллектуальный поиск по документам: ключевые ситуации
ИИ-поиск для бизнеса решает системную проблему фрагментации корпоративной информации и снижает затраты ресурсов на её поиск и использование. Разберём основные сценарии.
Единая поисковая точка доступа к корпоративным данным
Сотрудник получает единый интерфейс поиска по всем корпоративным источникам: базам знаний, файловым хранилищам, почтовым системам, тасктрекерам и архивам.
Система обрабатывает как структурированные, так и неструктурированные данные, включая данные в форматах PDF, Word, Excel, а также скан-копии и графические материалы. При наличии OCR поддерживается извлечение текста из изображений и отсканированных документов.
Ускорение процессов и концепция Zero-Touch
ИИ-поиск напрямую влияет на скорость работы команд, особенно в клиентских сценариях. Сотрудники быстрее находят нужную информацию и могут сразу применять её в работе: отвечать клиентам, обрабатывать заявки, принимать решения без задержек.
Например, оператор службы поддержки получает вопрос от клиента. Вместо поиска по разным системам он задаёт запрос и сразу получает готовую выжимку из регламента или инструкции. Это сокращает время ответа и снижает вероятность ошибки.
В результате:
- ускоряется обработка клиентских запросов (в Service Desk или на телефонной линии);
- повышается качество и единообразие ответов;
- растёт клиентская лояльность за счёт более быстрых и точных решений.
Снижается также количество ручных обращений внутри компании. Такой подход, который также называют Zero-Touch («нулевой контакт»), позволяет сотрудникам решать типовые вопросы самостоятельно, без подключения эйчаров, поддержки или экспертов.
Это дополнительно позволяет сократить нагрузку на HR-отдел и поддержку минимум в три раза, ускорить онбординг и уменьшить количество повторяющихся запросов.
Кейс: как Dodo Brands внедрили умный поиск и снизили нагрузку на команды
В Dodo Brands долгое время использовали собственную систему для работы со знаниями. Но со временем она перестала справляться с задачами бизнеса из-за слабого поиска, устаревшего интерфейса и ограниченных настроек доступа. Эти факторы замедляли работу и усложняли доступ к информации.
Компания решила перейти на полноценную систему управления знаниями и выбрала Minerva Knowledge. Ключевыми требованиями были:
- удобный и отзывчивый поиск;
- гибкое разграничение доступов;
- современный интерфейс;
- возможность собрать единую базу знаний.
В результате компания собрала и актуализировала все знания в одном месте, ускорила и повысила точность поиска за счёт работы со структурой и синонимами, а также получила аналитику по запросам и полезности контента. Это позволило снизить нагрузку на поддержку и ускорить работу операторов.
Итоги: эффективность поиска выросла с 6,5 до 7,1 балла за полгода, а уровень обслуживания (SLA) увеличился с 75 до 83%.
Отдельным направлением стало тестирование ИИ-бота для поддержки. Он использует базу знаний и помогает операторам быстрее отвечать на запросы.

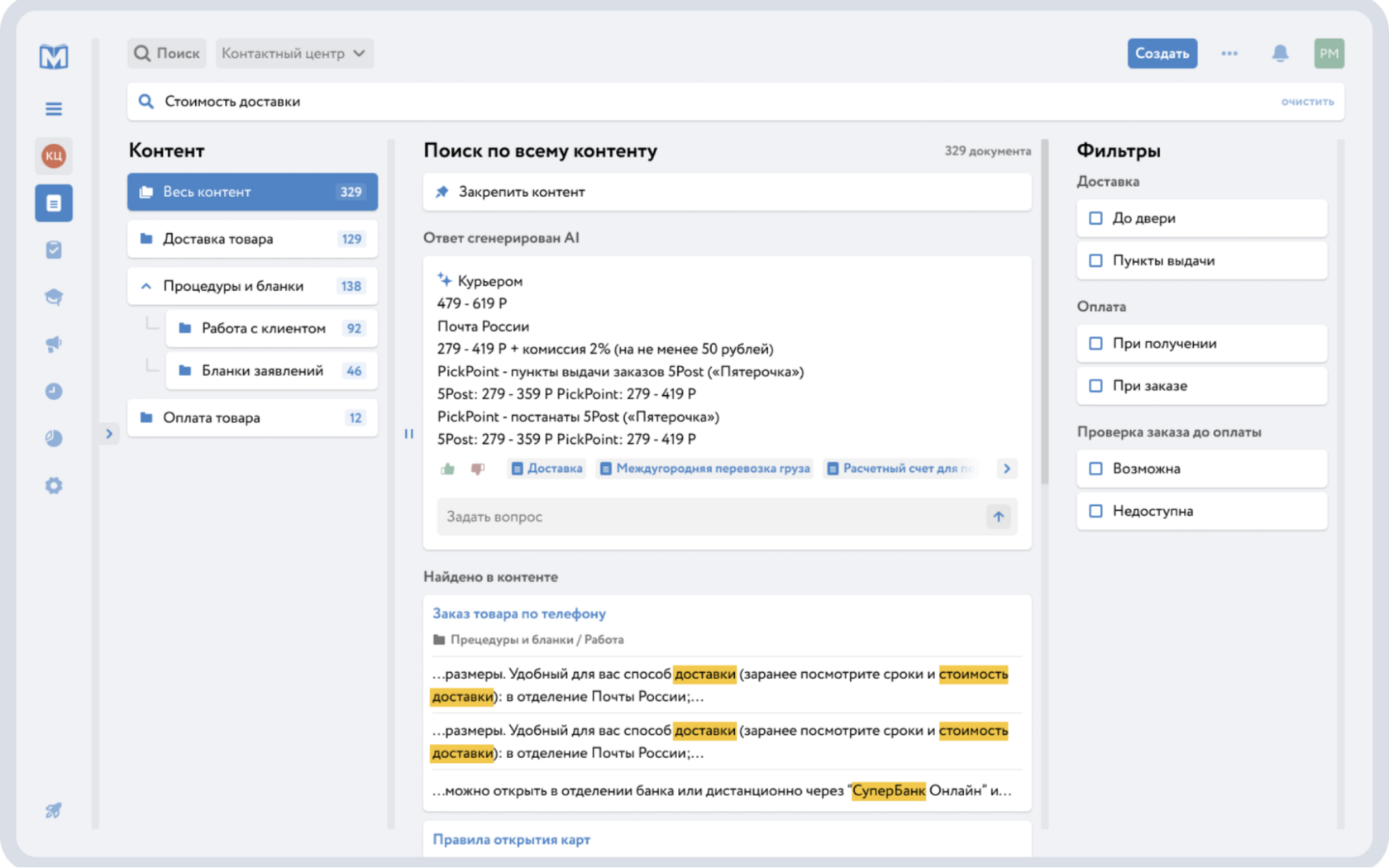
Умный поиск по документам: решения на рынке
В 2026 году компании всё активнее переходят от классических поисковых движков к платформам интеллектуального поиска. На международном рынке представлены разные классы решений, например Glean, Hebbia, Elastic с AI-расширениями и Azure AI Search. Они позволяют искать информацию по смыслу, работать с корпоративными источниками и использовать генеративные модели для формирования ответов.
На российском рынке такие сценарии чаще реализуются не по отдельности, а в рамках комплексной системы из нескольких компонентов: интеллектуального поиска, корпоративной базы знаний и ИИ-ассистента.
Примером служит экосистема Minervasoft. Её фундаментом выступает платформа для управления знаниями Minerva Knowledge, которая является единым источником данных и объединяет документы, инструкции и кейсы в одном пространстве.
При этом она поддерживает импортонезависимую архитектуру, соответствует требованиям корпоративной безопасности и включена в реестр отечественного ПО.
На платформе Minerva Knowledge работает система интеллектуального поиска и AI-ассистент Minerva Copilot, которые используют данные из базы знаний для формирования быстрых и точных ответов. По запросу клиента можно подключить дополнительные внешние источники для работы поиска и интеллектуального ассистента.
ИИ-поиск объединяет в себе несколько ключевых технологий:
- векторный поиск для работы со смыслом;
- языковые модели (LLM) для генерации ответов;
- RAG-подход, при котором ответы формируются на основе внутренних данных компании.
За счёт этого Minerva Copilot не просто ищет документы, а извлекает нужную информацию и формирует готовый ответ с опорой на проверенные источники. Это снижает риск ошибок в рабочих процессах.
Minerva Copilot встраивается в привычные системы — CRM, Help Desk, корпоративные порталы — и помогает сотрудникам быстрее находить ответы без переключения между инструментами.
Так, если в базе знаний обновляется информация, например меняется шаблон NDA или внутренний регламент, то ассистент сразу начинает использовать новую версию без дополнительной настройки.
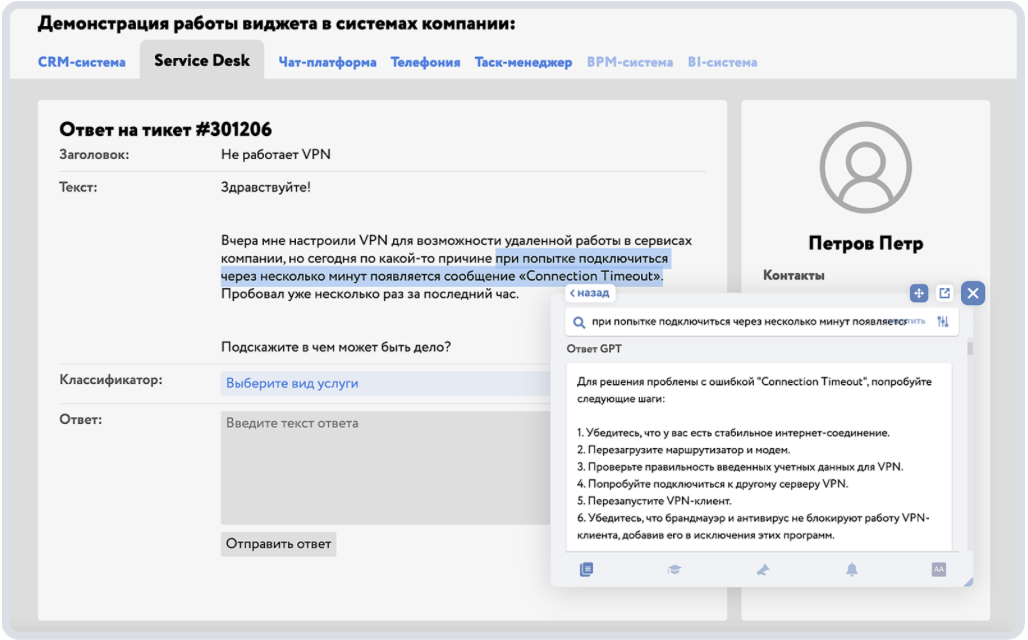
Кроме того, интеллектуальный поиск и Copilot можно использовать и во внешних интерфейсах, например на клиентских порталах. В этом случае он генерирует ответы на запросы клиентов, снижая нагрузку на первую линию поддержки.
На что ориентироваться при выборе системы интеллектуального поиска
При выборе системы интеллектуального поиска компании обычно оценивают такие параметры, как:
- Интеграция с корпоративными источниками данных.
- Качество поиска и релевантность выдачи.
- Поддержка современных технологий.
- Ролевая модель доступа.
- Варианты развёртывания.
- Информационная безопасность и соответствие требованиям.
- Совокупная стоимость владения (TCO).
Итог
Интеллектуальный поиск становится инфраструктурным инструментом для компаний, работающих с большим объёмом корпоративных знаний и документов. Замена стандартного поиска интеллектуальным повышает производительность сотрудников, ускоряет внутренние процессы и снижает операционные издержки за счёт более точного и быстрого доступа к информации.




