
Тема баз данных для ИИ охватывает принципиально разные классы задач, которые нередко смешивают в одном обсуждении. Хранилище для обучения нейросети, векторная база данных для RAG / семантического поиска и корпоративная база знаний — это разные архитектурные решения, с разными требованиями к данным, инфраструктуре и компетенциям команды. Каждый из этих сценариев требует отдельного рассмотрения.
В статье разберём, какие типы хранилищ применяются в ИИ-цепочках обработки данных, чем отличаются требования к данным для обучения модели от требований к данным для её работы в промышленной эксплуатации, как устроена архитектура RAG и почему для большинства корпоративных сценариев существует проблема не в выборе модели, а в качестве данных.

Время прочтения: 18 минут
Краткое содержание
Какие базы данных используются для ИИ
База данных для обучения ИИ vs база данных для RAG
Базы данных для RAG: как ИИ-агент находит и использует данные
Требования к данным и знаниям компании: что должно быть в базе, чтобы ИИ не галлюцинировал
Безопасность и развёртывание базы данных для корпоративного ИИ
Экосистема Minervasoft: база знаний + умный поиск + аудит данных
Заключение
Какие базы данных используются для ИИ
База данных для обучения ИИ vs база данных для RAG
Базы данных для RAG: как ИИ-агент находит и использует данные
Требования к данным и знаниям компании: что должно быть в базе, чтобы ИИ не галлюцинировал
Безопасность и развёртывание базы данных для корпоративного ИИ
Экосистема Minervasoft: база знаний + умный поиск + аудит данных
Заключение
Какие базы данных используются для ИИ
В технологическом смысле база данных для ИИ или нейросети — это любое хранилище, которое участвует в каждом этапе работы с ИИ: при обучении модели, при подготовке и разметке данных, при индексации корпоративного контента или в режиме реального времени, когда обученная модель обращается к внешним данным при каждом запросе.
Практически все сценарии использования данных в промышленном ИИ укладываются в два класса, которые различаются по целям, требованиям к данным и архитектурным решениям.
Сценарий № 1: данные для обучения модели
Цель — сформировать обучающую выборку, на которой модель итеративно оттачивает свои веса. Качество модели напрямую определяется качеством обучающих данных: их объёмом, репрезентативностью, полнотой разметки и степенью чистоты. Сюда же относится дообучение (файнтюнинг) уже готовой модели на специализированных данных для адаптации к конкретной предметной области, стилю или формату ответов.
Этот сценарий требует значительных инвестиций в GPU-кластеры, команду инженеров по машинному обучению, инфраструктуру для версионирования данных и воспроизводимости экспериментов, процессы разметки и контроля качества данных.
Сценарий № 2: данные для работы уже обученной модели
Цель — обеспечить LLM актуальными и релевантными данными в момент формирования ответа, не переобучая её. Для этого используется архитектура RAG (Retrieval-Augmented Generation): в момент запроса система извлекает из внешнего хранилища релевантные фрагменты и передаёт их модели как часть контекста.
Этот сценарий значительно практичнее для корпоративной среды. Он не требует сложной инфраструктуры, не предполагает большой команды специалистов и позволяет использовать актуальные корпоративные данные без периодического переобучения модели. Для большинства бизнес-задач — ИИ-ассистент для поддержки, поиск по внутренним документам, автоматизация ответов на типовые запросы — именно этот подход экономически оправдан.
Типы хранилищ, которые используют в ИИ-сценариях
Не существует универсальной базы данных для всех ИИ-сценариев. Разные типы хранилищ оптимизированы под разные задачи, и компании, как правило, используют их в комбинации.
Каждый тип хранилища оптимизирован под конкретный класс операций. Векторная база данных эффективна для поиска по смысловой близости, но не предназначена для хранения метаданных. Реляционная база данных хорошо управляет структурированными данными и правами доступа, но не поддерживает векторный поиск.
А поисковая система типа Elasticsearch обеспечивает точный полнотекстовый поиск по ключевым словам, но не заменяет семантический поиск по смысловой близости. Поэтому компании зачастую комбинируют эти классы решений, чтобы закрыть весь ряд бизнес-задач.
Типовая архитектура корпоративной системы с RAG выглядит так: объектное хранилище содержит исходные документы, векторная база данных хранит векторные представления фрагментов, реляционная база данных управляет метаданными и правами доступа, Elasticsearch обеспечивает гибридный поиск там, где нужна точность по ключевым словам. Все компоненты работают в связке через оркестрационный слой.
База данных для обучения ИИ vs база данных для RAG
Два сценария работы с данными в ИИ предъявляют принципиально разные требования к хранилищам, инфраструктуре и командам. Первый — обучение модели на размеченных примерах, где качество результата определяется объёмом, репрезентативностью и чистотой обучающей выборки. Второй — дополненная генерация с извлечением, где модель не переобучается, а получает актуальные корпоративные документы в контекст при каждом запросе.
Разберём ключевые различия.
Бизнесу только изредка нужен первый сценарий — полное обучение модели с нуля.
Современные LLM (которые можно развернуть локально) уже обладают широкими базовыми компетенциями: рассуждением, суммаризацией, генерацией текста и визуальных материалов. Обучать модель с нуля имеет смысл только в специфических обстоятельствах:
- задача требует глубокой специализации в узкой предметной области, с нестандартной терминологией, которой нет в обучающих данных публичных моделей;
- критичны ограничения по задержке и размеру модели для локальной обработки на устройстве;
- необходим полный контроль над архитектурой и весами модели по регуляторным причинам или соображениям безопасности.
Во всех остальных случаях дообучение и настройка инструкций — значительно более экономичный путь. А для большинства корпоративных задач оптимальным решением является именно RAG поверх качественной базы знаний. В таком формате модель не требует ни обучения, ни дообучения, обеспечивает актуальность данных без файнтюнинга и даёт ответы со ссылками на конкретные источники.
Базы данных для RAG: как ИИ-агент находит и использует данные
RAG — это архитектурный подход, при котором LLM, вместо того чтобы полагаться исключительно на знания, закодированные в весах при обучении, работает с релевантными фрагментами, извлечёнными из внешнего хранилища непосредственно во время обработки запроса.
Этот подход решает два ключевых ограничения LLM.
Во-первых, знания модели зафиксированы на момент обучения и не обновляются. Она не знает ни о событиях после завершения обучения, ни о внутренних данных компании.
Во-вторых, модель склонна к галлюцинациям: при отсутствии точных знаний она генерирует правдоподобно звучащий, но фактически неверный текст. RAG снижает оба риска, подавая модели актуальный и верифицированный контекст.
Принципиально важно: качество ответа системы с дополненной генерацией определяется в первую очередь качеством извлечения, а не выбором модели. Если механизм извлечения возвращает нерелевантные или неполные фрагменты, то модель формирует ответ на основе ошибочного контекста, поэтому улучшение или дообучение самой модели ситуацию не исправит.
Пайплайн обработки запроса при RAG
Этап индексации выполняется заранее — при загрузке документов:
- Исходные документы извлекаются из хранилища и проходят предобработку: очистку форматирования, оптическое распознавание текста для сканов, структурный разбор таблиц.
- Документы разбиваются на фрагменты. Как правило, это 256–1 024 токена с перекрытием в 10–20% для сохранения контекста на границах фрагментов.
- Каждый фрагмент преобразуется в векторное представление с помощью модели векторизации.
- Векторное представление вместе с метаданными (идентификатор документа, дата, раздел, автор, права доступа) сохраняется в векторной базе данных.
Этап обработки запроса выполняется в реальном времени:
- Запрос пользователя преобразуется в векторное представление той же моделью векторизации, что использовалась при индексации.
- В векторной базе данных для ИИ выполняется поиск ближайших соседей — находятся фрагменты с максимальной смысловой близостью к запросу.
- Результаты фильтруются по метаданным: правам доступа пользователя, временному диапазону, типу документа.
- Отобранные фрагменты формируют контекст, который передаётся модели вместе с запросом и системными инструкциями.
- Большая языковая модель (LLM) формирует ответ, опираясь на предоставленный контекст.
- Ответ возвращается пользователю вместе со ссылками на исходные документы.
В корпоративном контуре этот подход реализован в умном помощнике Minerva Copilot: ИИ‑ассистент использует базу знаний Minerva Knowledge и другие подключённые корпоративные источники как хранилище фрагментов.
При каждом запросе пользователя Copilot выполняет семантический поиск по этим фрагментам с учётом прав доступа, формирует контекст и генерирует ответ на основе актуальных корпоративных знаний, а не веб-данных.
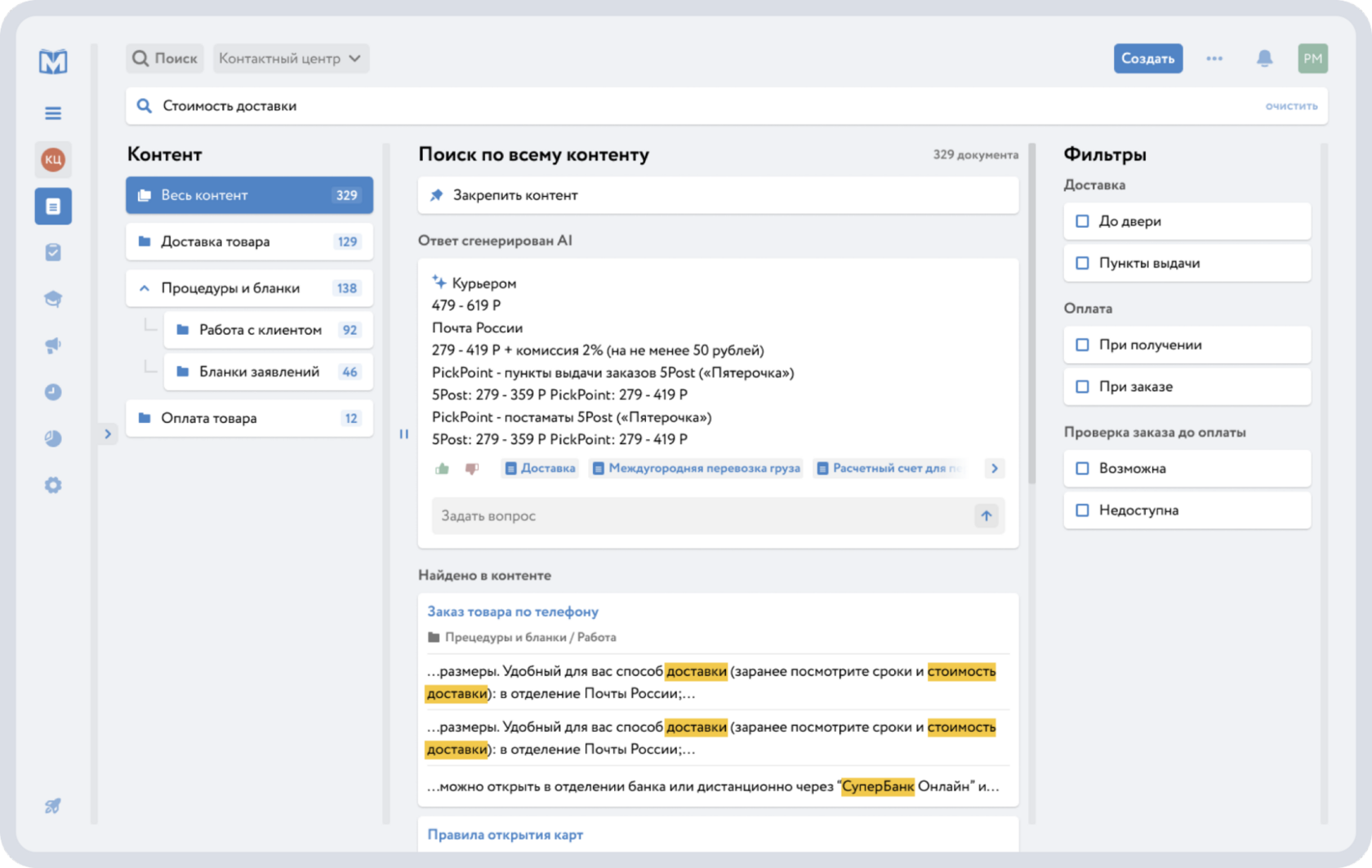
Пример ИИ-сниппета, сгенерированного на корпоративных материалах
Требования к базе данных для RAG и корпоративного ИИ-агента
Для качественной работы RAG база данных должна подходить под несколько требований.
Однако даже идеально настроенный механизм извлечения не поможет, если сами документы в базе данных содержат ошибки, дубли или устаревшую информацию.
Требования к знаниям компании: что должно быть в базе, чтобы ИИ не галлюцинировал
RAG действительно снижает количество галлюцинаций, но только если модель получает качественные знания. Если в базе находятся устаревшие инструкции, противоречивые документы или плохо структурированный контент, система будет воспроизводить те же ошибки, независимо от качества используемой модели.
По данным исследования McKinsey State of AI 2025, ИИ используют 78% организаций, однако лишь немногие смогли масштабировать его использование и получить существенное влияние на финансовые показатели. Среди факторов, которые на это повлияли, McKinsey выделяет ключевым именно качество данных и управления знаниями.
Рассмотрим основные требования к знаниям и контенту компании, которые помогают ИИ находить корректную информацию, понимать контекст и давать точные ответы.
Актуальность
ИИ с RAG может опираться только на ту информацию, которая есть в базе знаний. Если в систему загружены устаревшие регламенты, старые выгрузки из Excel или неактуальные инструкции, ассистент будет воспроизводить именно их.
Поэтому важно организовать процессы актуализации корпоративной информации: назначать владельцев контента, регулярно пересматривать материалы и своевременно выводить из использования устаревшие версии документов.
Такие задачи обычно решаются средствами управления знаниями: жизненным циклом статей, согласованием изменений, публикацией новых версий и архивированием устаревшего контента.
Конкретика вместо общих формулировок
Для ИИ особенно важна операциональная конкретика: система лучше отвечает тогда, когда в содержании зафиксированы точные действия, условия, исключения, параметры и сценарии, а не общие описания процесса. Пошаговые инструкции с указанием платформы, разделов меню и условий применения извлекаются и воспроизводятся значительно надёжнее, нежели абстрактные формулировки.
Проблема здесь решается не дообучением модели, а корректировкой процессов управления знаниями: шаблонами статей, правилами описания процедур, полями для условий применения и единым стандартом оформления инструктивного контента. Поддержать это помогают совместные редакторы статей с шаблонами, контроль полноты заполнения карточек контента и инструменты контроля качества для хранилища знаний.
Понятная структура документа
Даже качественный по смыслу материал теряет ценность для ИИ, если в нём отсутствует формальная структура, например если заголовки выделены визуально, но не размечены как уровни документа, разделы не отделены друг от друга.
Для устранения этой проблемы нужны не только редакторские правила, но и программные средства, которые поддерживают структурную разметку: системы управления знаниями, текстовые редакторы с семантическими стилями, а также инструменты нормализации контента при миграции из текстовых файлов, PDF и других форматов.
Наличие контекста и связей
ИИ обрабатывает документы по отдельности, поэтому при отсутствии явных связей между материалами он не видит полной картины и не может надёжно достроить логический вывод. Если статья ссылается на категорию, исключение, список товаров или смежный регламент, но сама связь не оформлена ссылкой, врезкой или встроенным фрагментом, то ответ будет неполным даже при наличии нужной информации в одном из разделов базы.
Отсюда требование к контенту: критические зависимости между статьями должны быть выражены явно — через перекрёстные ссылки, вставки из связанных материалов, блок «Сопутствующие статьи» и другие навигационные блоки. Это поддерживается средствами работы со связями между знаниями, системой внутренних ссылок, механизмами связывания статей и компонентной сборкой контента.
Машиночитаемые таблицы и изображения
Таблицы, сканы, схемы, снимки экрана и встроенные фрагменты страниц могут быть некорректно интерпретированы ИИ, если они не сопровождаются текстовым слоем или поясняющим описанием.
Поэтому важная информация должна дублироваться или сопровождаться текстом:
- Для встроенных фрагментов страницы — описанием содержимого.
- Для таблиц — текстовой расшифровкой ключевых строк и столбцов.
- Для изображений и сканов — качественным распознаванием текста или исходным текстовым документом.
В этом помогают модули распознавания текста (OCR), платформы интеллектуальной обработки документов, средства разбора таблиц, подписи и инструменты обогащения контента текстовыми описаниями.
Термины и права доступа
Корпоративный контент должен быть понятен ИИ в терминологическом отношении. Аббревиатуры, внутренние сокращения, профессиональный жаргон и продуктовые обозначения нужно расшифровывать или фиксировать в словаре терминов, иначе модель не сможет корректно интерпретировать запрос и связать его с нужными материалами. Этот пункт особенно важен в предметных областях с насыщенной внутренней терминологией, где один и тот же термин может иметь одно или несколько локальных значений внутри компании.
Отдельное требование — разметка информации по типу доступа: знания должны быть не просто собраны, но и дифференцированы по ролям, подразделениям и сценариям использования, чтобы ИИ не показывал пользователю контент вне его полномочий.
Обычно это обеспечивается средствами разграничения прав и ролей, ролевой моделью доступа в системе управления знаниями, разграничением публикаций по аудиториям.
Самостоятельно компании не всегда могут соблюсти все требования к контенту для полноценного внедрения ИИ в корпоративный контур. Команда Minerva Result помогает провести аудит знаний и оценить готовность корпоративных данных к подключению ИИ-ассистента по четырём направлениям.
- Готовность к применению ИИ. Анализ имеющихся данных на предмет их структурной организованности и понятности с точки зрения алгоритмов искусственного интеллекта и машинного обучения.
- Культура менеджмента знаний. Воспринимают ли сотрудники базу знаний как рабочий инструмент, насколько стабильно они обращаются к ней в ежедневной работе и какие системные проблемы мешают более широкому использованию знаний в компании.
- Качество знаний. Насколько полно знания покрывают ключевые сценарии, насколько регулярно обновляются критичные материалы и где находятся основные проблемные зоны в содержании базы.
- Пользовательский опыт работы со знаниями. Насколько легко пользователям найти нужную информацию, как устроена навигация и поиск, нет ли барьеров, связанных с интерфейсом, функционалом платформы или ограничениями доступа.
По результатам аудита компания получает отчёт с рекомендациями, пошаговый план улучшения системных процессов работы со знаниями, а также консультацию экспертов Minerva Result с ответами на вопросы и разъяснением предложенных изменений.
Большинство компаний, которые приходят к нам перед внедрением ИИ-ассистента, искренне убеждены, что с их данными всё в порядке. Документы есть, база знаний есть. Но когда мы начинаем аудит, выясняется, что значительная часть этих документов либо устарели, либо дублируют друг друга с расхождениями, либо существуют только в головах конкретных сотрудников и нигде не зафиксированы.
Проблема не в том, что компании не хотят порядка в знаниях. Проблема в том, что без внешнего давления — регуляторного, технологического или конкурентного — этот порядок не возникает сам по себе. Внедрение ИИ становится таким давлением: оно делает видимыми все накопленные за годы проблемы с данными и создаёт реальный стимул их решить.
Денис Кучеров, директор проектов Minerva Result
Однако качество ответов — не единственная задача корпоративного ИИ. Не менее важны вопросы безопасности и контроля доступа.
Безопасность и развёртывание базы данных для корпоративного ИИ
Системы с RAG работают с живыми корпоративными данными в режиме реального времени. При каждом запросе механизм извлечения обращается к реальным документам компании: договорам, кадровым данным, финансовой отчётности, техническим спецификациям. Это принципиально отличает такие системы от статических приложений — поверхность атаки и риски утечки данных значительно шире.
IBM в своих рекомендациях по корпоративным системам с дополненной генерацией отдельно подчёркивает, что контроль доступа, шифрование и механизмы аудируемости — это не дополнительные функции, которые можно добавить позже, а обязательная часть базовой архитектуры, о которой нужно думать изначально. Добавление их постфактум требует значительных переработок и, как правило, приводит к компромиссам в качестве реализации и безопасности.
Ролевая модель доступа и фильтрация по правам
Корпоративная база информации содержит документы с разными уровнями конфиденциальности и разными аудиториями. Финансовые отчёты доступны финансовому отделу, кадровые политики с персональными данными — только HR-специалистам, а технические спецификации — IT-командам.
Ролевая модель доступа должна быть встроена в слой извлечения: при поиске релевантных фрагментов система учитывает права конкретного пользователя и никогда не включает в контекст модели фрагменты из документов, на просмотр которых у него нет разрешения. Проверка прав только на уровне интерфейса — после того как фрагмент уже попал в контекст модели — недостаточна и создаёт риск утечки через содержимое ответа.
Локальное развёртывание и закрытый контур
Для данных высокой степени конфиденциальности (персональные данные, медицинские записи, юридические документы, стратегические материалы) необходимо сделать так, чтобы они не покидали корпоративный контур. Есть несколько подходов: локальное развёртывание LLM (открытые модели высокого качества) или использование облачных сервисов с гарантиями изоляции данных и договорными обязательствами о неиспользовании данных для обучения.
При использовании внешних программных интерфейсов необходимо явно фиксировать, какие данные и в каком виде передаются внешним поставщикам, и проверять соответствие условий обработки данных требованиям внутренней политики безопасности и применимого законодательства.
Как экосистема Minervasoft помогает подготовить качественного ИИ-ассистента
Качество ответов ИИ-ассистента зависит не только от модели, но и от того, на какие корпоративные знания он опирается. Если знания разрозненные, устаревшие или неудобные для поиска и машинной интерпретации, то даже сильная модель будет давать некорректные ответы.
Поэтому на практике внедрение ИИ обычно начинается не с разработки интерфейса помощника и настройки оркестрации, а с подготовки базы знаний и процессов работы с ней.
В этом контексте продукты и услуги Minervasoft можно рассматривать как последовательные элементы для решения одной задачи: сначала оценить состояние знаний и процессов, затем привести контент в рабочее состояние, а после этого подключать ИИ-помощника к корпоративным источникам.
Minerva Knowledge — источник корпоративных знаний, а именно: регламентов, инструкций и процедур с единой структурой, версионированием, метаданными и разграничением доступа. Платформа обладает всем необходимым функционалом, который требуется для качественной подготовки данных к внедрению ИИ.
Платформа Minerva Knowledge стала источником знаний для ИИ-бота клиентской поддержки Dodo Brands (сеть пиццерий Dodo Pizza и цифровые кофейни Drinkit). В результате внедрения компания увеличила уровень сервиса на 9% и повысила эффективность поиска на 10%.

Minerva Copilot — ИИ-ассистент с архитектурой RAG поверх Minerva Knowledge. Помощник обучается на корпоративных знаниях компании и формирует ответы на основе базы знаний и других подключённых корпоративных источников. Он может встраиваться в рабочие системы сотрудников: в CRM, инструменты службы поддержки, внутренние порталы и в другие корпоративные инструменты.
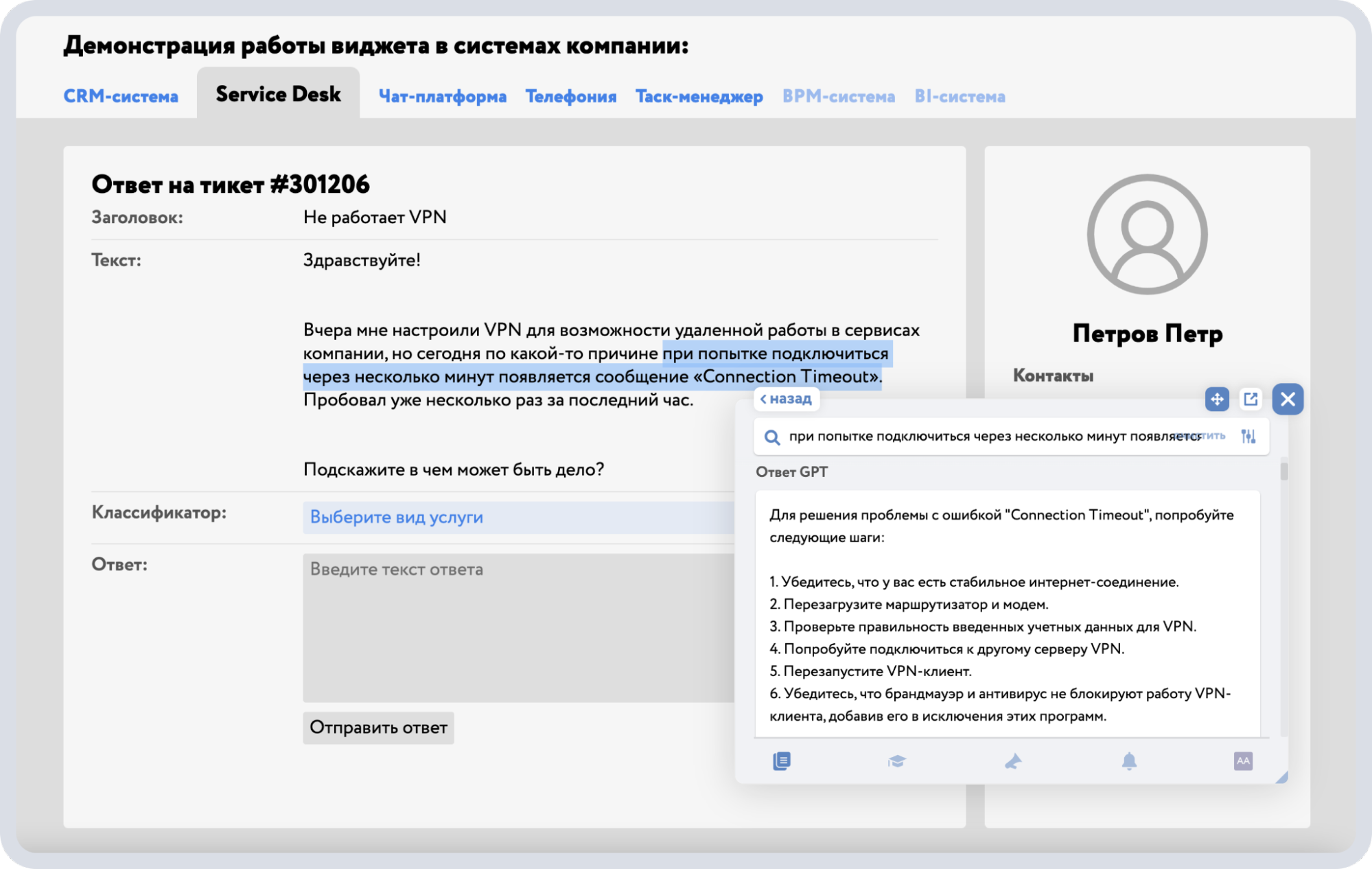
Пример интеграции ИИ-помощника в корпоративный софт
Minerva Result — экспертная команда, которая проведёт аудит готовности корпоративных данных к внедрению ИИ-ассистента в течение двух месяцев, выполнит комплексный проект по оптимизации и актуализации знаний и процессов, подключит ИИ-помощника и измерит полученный эффект на ИИ-инструментах.
Таким образом компания сможет избежать ошибок: запуска пилота на сырых данных, фиксации ошибок ИИ, срочной доработки знаний и повторного пилота. Если перед запуском пилота сразу поставить в приоритет знания, то можно предотвратить потери бюджета, времени и доверия к ИИ.
Заключение
База данных для ИИ — это не единая технология, а класс архитектурных решений, выбор которых определяется конкретным сценарием. Для корпоративного ИИ-ассистента обучение модели с нуля практически никогда не требуется: достаточно готовой большой языковой модели, качественно подготовленной базы знаний и правильно выстроенного механизма извлечения с контролем доступа.
Главное ограничение большинства корпоративных внедрений — не технологии, а данные. Качество ответов ИИ-ассистента определяется качеством источников, на которых он работает, и никакое улучшение модели это не компенсирует.




